FormulaOne: The Groundbreaking Benchmark for AI Reasoning Beyond Competitive Programming
In the world of artificial intelligence, the capabilities of frontier AI models have dazzled us with their breadth of knowledge. Yet, how close are these models to achieving true human-like reasoning, especially in complex scenarios? A new research paper titled FormulaOne: Measuring the Depth of Algorithmic Reasoning Beyond Competitive Programming by Gal Beniamini and colleagues seeks to answer this critical question by introducing a challenging benchmark that focuses on real-world problems instead of traditional programming puzzles.
The Motivation Behind FormulaOne
While competitive programming competitions offer a unique skill set, the problems presented often fall short of reflecting the depth and complexity of real-world scenarios that expert human problem-solvers tackle. The researchers argue that to push the boundaries of what AI can achieve, we need problems that require profound multi-step reasoning steps, mathematical insight, and intricate algorithm design. This is where FormulaOne comes into play.
A New Benchmark for AI
FormulaOne includes a variety of algorithmic challenges that lie at the intersection of graph theory, logic, and complex algorithms. Importantly, the problems are generated from Monadic Second-Order (MSO) logic on graphs, which provides a robust framework for automatic problem generation at a large scale. This aspect not only ensures diversity in problems but also aligns with commercial interest areas such as routing, scheduling, and network design.
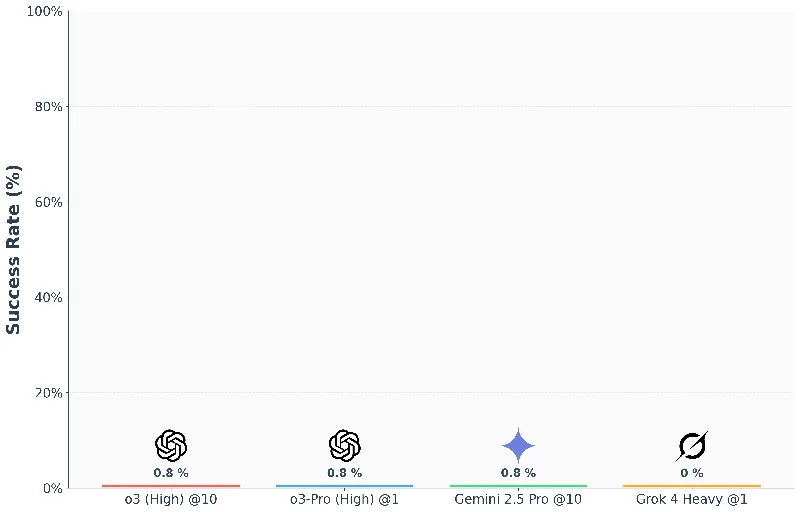
Notably, the benchmark contains tasks with rigorous standards, demanding extensive reasoning which causes even some of the state-of-the-art models to falter—former champions like OpenAI's o3 solving less than 1% of the questions. This stark statistic illustrates how much farther we need to go to bridge the gap between AI’s current capabilities and human-like reasoning.
Insights into AI Performance with FormulaOne
The findings from evaluating frontier reasoning models on FormulaOne are illuminating. Despite impressive ratings in competitive programming, these models struggle with deeper algorithmic reasoning tasks. This highlights a significant limitation: competitive programming prowess doesn't equate to high-level problem-solving skills needed for more complex real-world applications.
The Significance of Problem Complexity
One of the unique features of FormulaOne is its direct tie to theoretical computer science, particularly the Strong Exponential Time Hypothesis (SETH). This connection means that solving these problems may not only result in practical applications but could also challenge longstanding theoretical notions in computer science.
The development of the warm-up version, FormulaOne-Warmup, offers an introductory set of simpler tasks for researchers, showing that these benchmarks can be tailored to gradually elevate the difficulty of algorithmic challenges as AI models evolve.
A Call to Action for Future Research
The research concludes with a call for the AI community to adopt new benchmarks capable of capturing deeper levels of algorithmic reasoning, pushing researchers to develop sophisticated methods beyond simple competitive programming. As the landscape of AI evolves, so must the metrics and challenges we present to it, ensuring the next generation of models can tackle the hard problems of our time.
In essence, FormulaOne represents a bold step forward in not just evaluating, but actively enhancing AI's capability to think and reason at levels akin to human experts.

